ProtoSound
Project Description
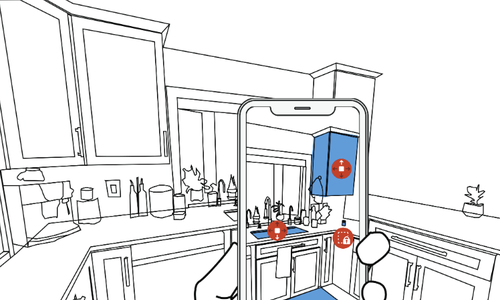
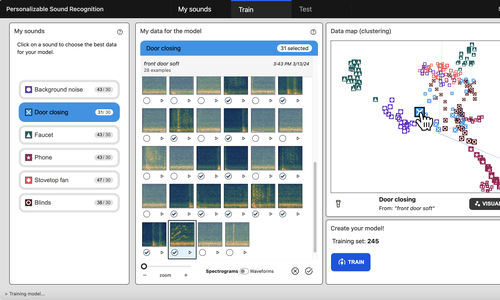
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work and a survey we conducted with 472 DHH participants. We characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art approaches (e.g., +9.7% accuracy on the first dataset). To assess real-world performance, we then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts.
- Team
-
 Jon E. Froehlich · PI
Jon E. Froehlich · PI
 Leah Findlater · Co-PI
Leah Findlater · Co-PI
 Dhruv Jain · Lead
Dhruv Jain · Lead
- Funding
-
")
Publications

ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users
Proceedings of CHI 2022 | Acceptance Rate: 404.9% (2579 / 637)
PDF arXiv doi Cite ProtoSound Personalizing Sound Recognition
Related Projects