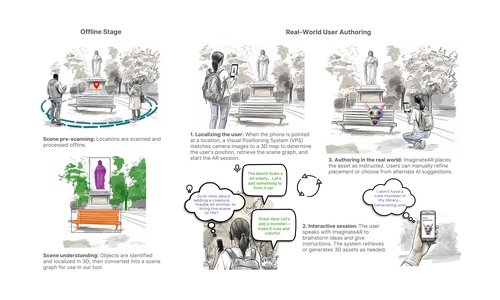
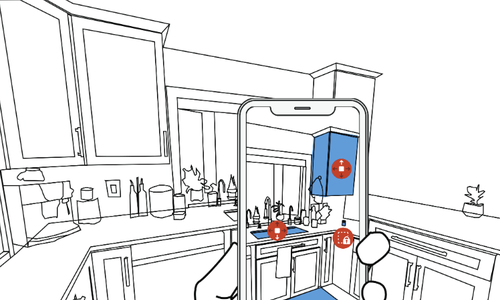
GazePointAR: A Context-Aware Multimodal Voice Assistant for Pronoun Disambiguation in Wearable Augmented Reality
Proceedings of CHI 2024 | Acceptance Rate: 26.3% (1060 / 4028)
 Jon E. Froehlich · PI
Jon E. Froehlich · PI
 Jaewook Lee · Lead
Jaewook Lee · Lead
Proceedings of CHI 2024 | Acceptance Rate: 26.3% (1060 / 4028)



May 15, 2024 | CHI
Honolulu, Hawaiʻi